3. Music Audio LLMs#
So, how can we feed audio signals to a LLM? It’s really the same as we did with images. We need to somewhat find a way to represent the audio signal in a vector sequence, \(\mathbf{H}_\mathtt{a}\) and perhaps feed it with some text representation \(\mathbf{H}_\mathtt{q}\).
3.1. Salmonn#
On a high level, Salmonn [TYS+23] architecture seems just like LLaVa.
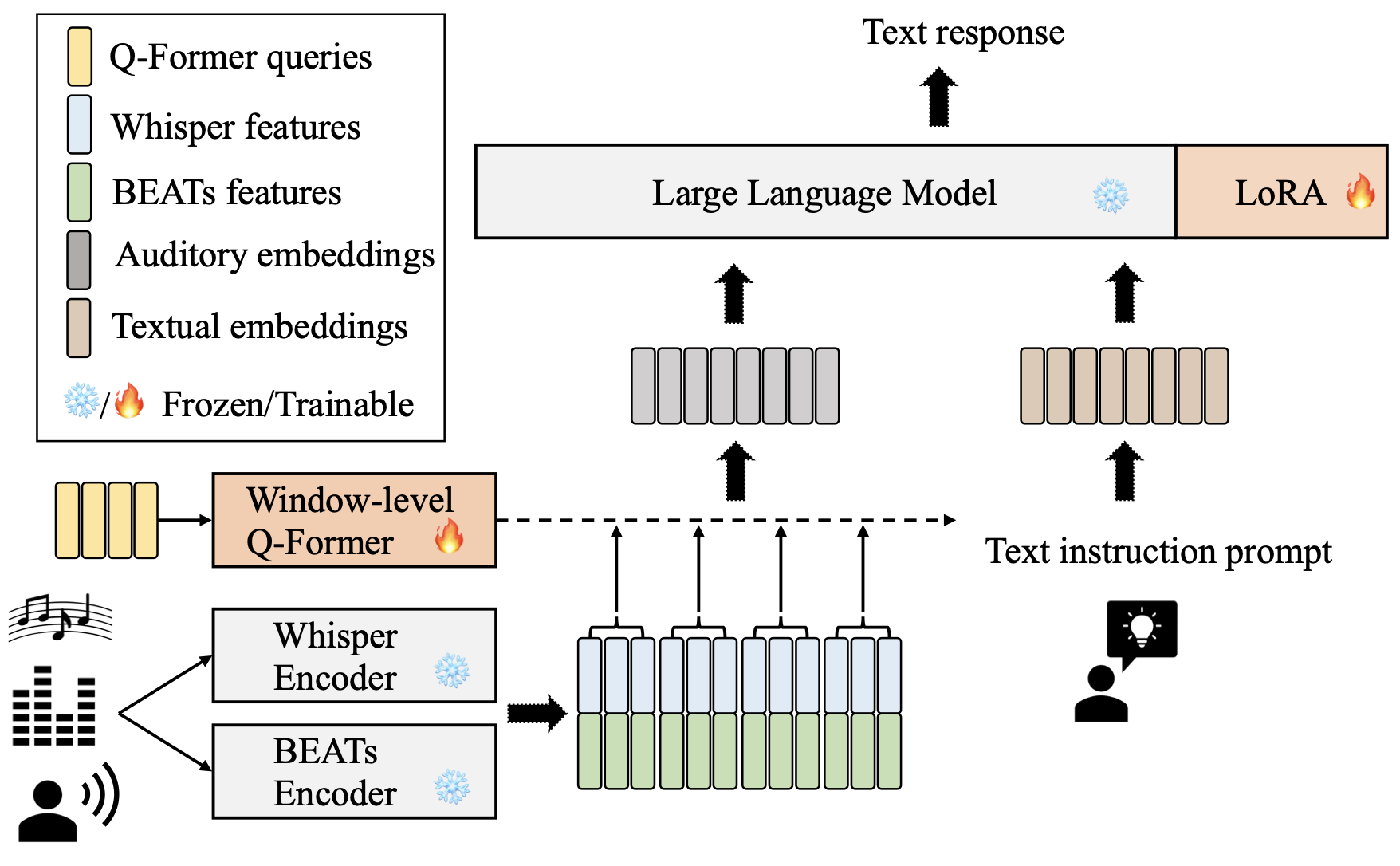
The authors of Salmonn used two complementary audio models – Whisper (a model for speech recognition, [RKX+23]) and BEATs (general audio encoder, [CWW+22]). With these two audio models, Salmonn can perform speech, audio, and music tasks.
Q-Former [LLSH23] is essentially equivalent to the image adaptor, with a bit more sophisticated computation on another transformer structure. By adopting Q-Former, we get not only matched the vector embedding size but also a fixed temporal length.
(Note: LoRA [HSW+21] is one of the efficient finetuning methods.)
3.2. LLark#
Unfortunately, you have to turn your head 90 degree clockwise to see the LLark architecture [GDSB23].
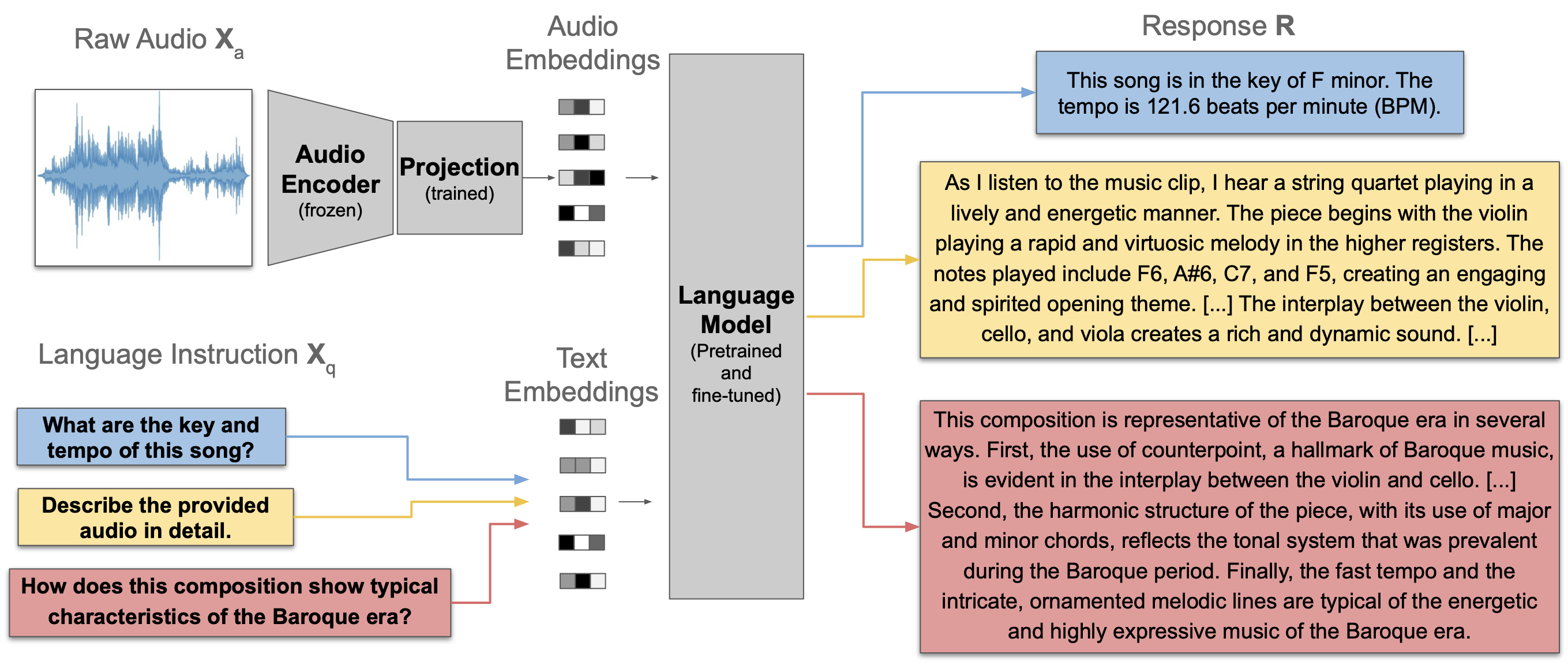
The “Audio Encoder (frozen)” is a Jukebox encoder [CDL21] that converts a raw audio \(\mathbf{X}_\texttt{a}\) to a sequence of 4800-dim vectors. After temporal downsampling, this sequence is again converted by a linear layer.