1.3. word2vec and BERTs: The Significant Hybrids#
The word2vec [MSC+13] and BERTs [DCLT18] are crucial steps towards LLMs. Compared to the previous language models, they are generally applicable to various language tasks.
1.3.1. Word Embeddings#
Word embeddings are dense vector representations of words that capture semantic and syntactic relationships between words. Typically, the size of word embeddings is between 64 and 1024.
1.3.2. Data#
For learning word representations like Word2Vec embeddings, large text corpora were used:
Wikipedia: The full English Wikipedia (~2.5B words)
These corpora provided the training data for learning dense vector representations of words based on their contexts.
For pretraining Transformer models like BERT, even larger datasets were used:
BooksCorpus: 800 million words from unpublished books
English Wikipedia: 2.5 billion words
Additional Web Data: Over 60 gigabytes of data from websites
1.3.3. Models and Training Objectives#
Both Word2Vec and BERT are trained to fill missing parts from the input texts. This means the training scheme is self-supervised learning, and we do not need human annotation - which means we can use a large-scale dataset.
1.3.3.1. Word2Vec#
The Word2Vec model is very simple. It’s a shallow neural network trained by either one of the two objectives:
Continuous Bag-of-Words (CBOW): Predicts the current word based on surrounding contexts.
Skip-gram: Predicts surrounding context words based on the current word.
1.3.3.2. BERT#
BERT is based on the Transformer architecture. It’s trained with two objectives:
Masked Language Modeling (MLM): Predicting randomly masked words based on context.
Next Sentence Prediction (NSP): Determining if two sentences were consecutive or not.
With the MLM loss, BERT learns a pretty good word embedding. With the NSP loss, BERT learns a nice sentence embedding.
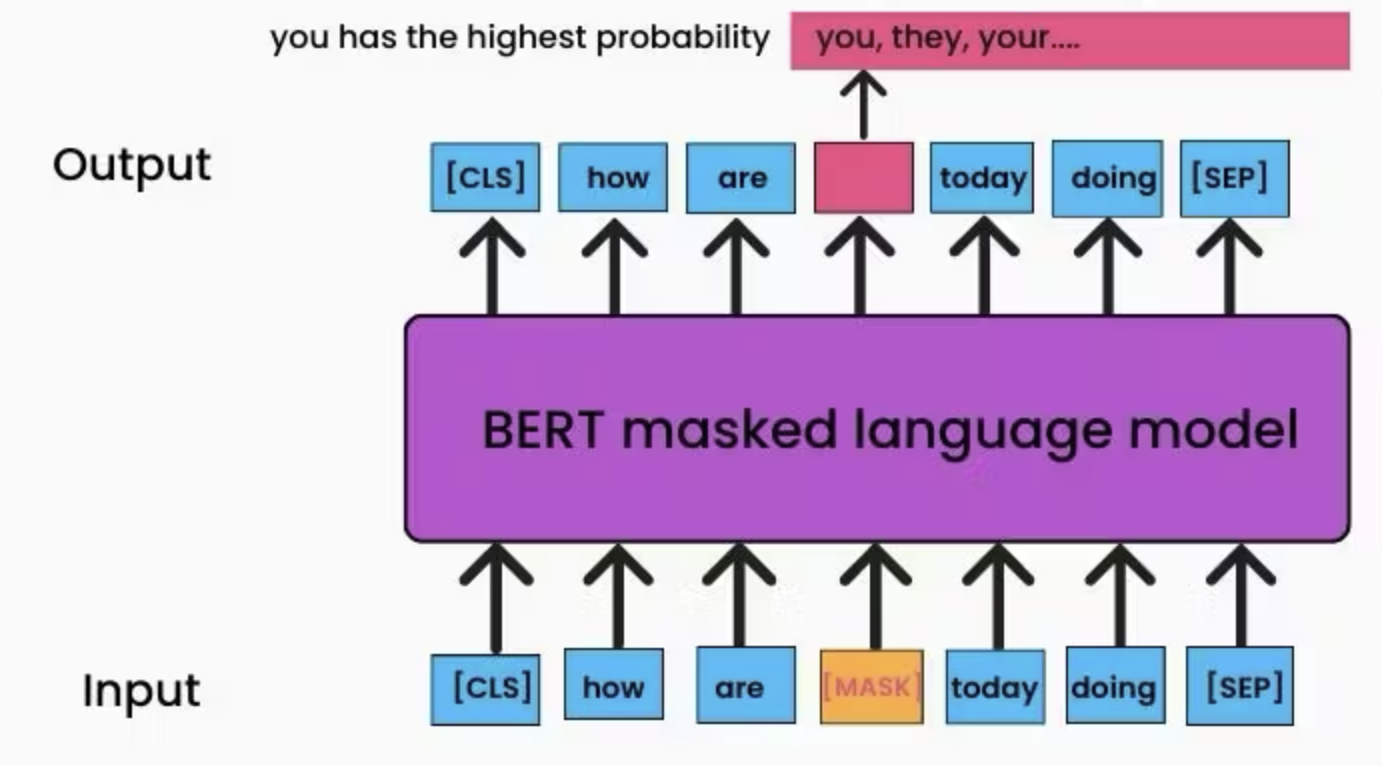 (
(In the image above, BERT has to predict what is the best word to be filled at the masked location. In my opinion, “they” wouldn’t be wrong, though “you” is perhaps more likely. And this opinion came from my English experience. BERT also needs to learn good word embeddings to perform the given task.
1.3.4. Why important? Pre-training vs. Finetuning#
Only with Word2Vec and BERT, many NLP tasks started to have two separate training stages: pre-training and finetuning.
Pre-training: Training a general model such as Word2Vec and BERT is called pre-training. This should be done on a large scale in terms of data, so that the model has good representations of many words in various contexts. To do that, one needs enough hardware.
Finetuning: One can use the trained word embedding model to solve downstream tasks. Compared to the pre-training stage, it’s simple - so simple (or it may seem so) that we don’t even call it “training” - we call it “tuning” (obviously, it’s also training).